AI顶会 “云”举行,优必选科技论文入选ICLR
受全球范围疫情爆发的影响,原定于4月25日在埃塞俄比亚首都亚的斯亚贝巴举行的人工智能顶会 ICLR 2020,宣布取消线下会议,完全改为线上。此前,2月7日在美国纽约举办的人工智能顶级会议AAAI2020,也采取了部分线上模式,让不能到场的学者远程参会。
虽然疫情让这些人工智能顶会充满变数,但丝毫不影响全球人工智能学者和研究人员的热情,他们提交了大量重要研究成果的论文。优必选悉尼大学人工智能研究中心今年也有数篇论文被人工智能顶会接收,其中,ICLR 2020有2篇,AAAI 2020有4篇,CVPR 2020有12篇。
ICLR(国际学习表征会议)于2013年成立,由Lecun,Hinton和Bengio三位神经网络的元老联手发起。近年来随着深度学习在工程实践中的成功,ICLR也在短短的几年中发展成为了神经网络的顶会。
今年,ICLR共收到了2594篇论文投稿,相比去年的1591篇论文投稿,增加了38.7%,其中687篇论文被接收,优必选悉尼大学人工智能中心有2篇论文被接收。
一:分段线性激活实质上塑造了神经网络的损失平面
摘要:理解神经网络的损失平面对于理解深度学习至关重要。本文介绍了分段线性激活函数是如何从根本上塑造神经网络损失平面的。我们首先证明了许多神经网络的损失平面具有无限的伪局部极小值,这些伪局部极小值被定义为经验风险比全局极小值更高的局部极小值。我们的结果表明,分段线性激活网络与已被人们充分研究的线性神经网络有着本质区别。实践中,这一结果适用于大多数损失函数中任何具有任意深度和任意分段线性激活函数(不包括线性函数)的神经网络。本质上,基本假设与大多数实际情况是一致的,即输出层比任何隐藏层都窄。此外,利用不可微分的边界将具有分段线性激活的神经网络的损失平面分割成多个光滑的多线性单元。所构造的伪局部极小值以底谷的形式集中在一个单元中:它们通过一条经验风险不变的连续路径相互连接。对于单隐层网络,我们进一步证明了一个单元中的所有局部最小值均构成一个等价类别;它们集中在一个底谷里;它们都是单元中的全局极小值。
二:理解递归神经网络中的泛化
摘要:在本文中,我们阐述了分析递归神经网络泛化性能的理论。我们首先基于矩阵1-范数和 Fisher-Rao 范数提出了一种新的递归神经网络的泛化边界。Fisher-Rao 范数的定义依赖于有关 RNN 梯度的结构引理。这种新的泛化边界假设输入数据的协方差矩阵是正定的,这可能限制了它在实际中的应用。为了解决这一问题,我们提出在输入数据中加入随机噪声,并证明了经随机噪声(随机噪声是输入数据的扩展)训练的一个泛化边界。与现有结果相比,我们的泛化边界对网络的规模没有明显的依赖关系。我们还发现,递归神经网络(RNN)的 Fisher-Rao 范数可以解释为梯度的度量,纳入这种梯度度量不仅可以收紧边界,而且可以在泛化和可训练性之间建立关系。在此基础上,我们从理论上分析了特征协方差对神经网络泛化的影响,并讨论了训练中的权值衰减和梯度裁剪可以如何改善神经网络泛化。
今年首场人工智能顶会AAAI 2020已于2月份在美国纽约举办,共评审了 7737 篇论文,最终接收了 1591 篇,接收率为 20.6%,优必选悉尼大学人工智能中心有4篇论文被接收。
一:阅读理解中的无监督域自适应学习
摘要:深度神经网络模型在很多阅读理解(RC)任务数据集上已经实现显著的性能提升。但是,这些模型在不同领域的泛化能力仍然不清楚。为弥补这一空缺,我们研究了阅读理解任务(RC)上的无监督域自适应问题。研究过程中,我们在标记源域上训练模型,并在仅有未标记样本的目标域应用模型。我们首先证明,即便使用强大的转换器双向编码表征(BERT)上下文表征,在一个域上训练好的模型也不能在另一个域实现很好的泛化能力。为了解决这个问题,我们提供了一种新的条件对抗自训练方法(CASe)。具体来说,我们的方法利用在源数据集上微调的 BERT 模型以及置信度过滤,在目标域中生成可靠的伪标记样本以进行自训练。另一方面,我们的方法通过跨域的条件对抗学习,进一步减小了域之间的分布差异。大量实验表明,我们的方法在多个大规模基准数据集上实现了与监督模型相当的性能。
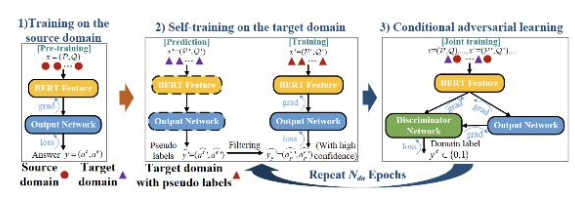
特征图:方法框架
二:Grapy-ML:跨数据集人体解析的图像金字塔相互学习
摘要:人体解析,即人体部位语义分割,因其具有广泛的潜在应用前景而成为一个研究热点。在本文中,我们提出一种新的图金字塔互学习(Grapy-ML)方法来解决标注粒度不同的跨数据集的人体解析问题。从人体层次结构的先验知识出发,我们将三层图结构按照粗粒度到细粒度的顺序进行叠加,设计出了一个新的图金字塔模型(GPM)。GPM在每一层都会利用自关注机制对上下文节点之间的相关性进行建模。然后,它采用了自上而下的机制来逐步细化各个层级的特征。GPM还使得高效的互学习成为可能。具体来说,为了在不同的数据集之间交换所学习到的粗粒度信息,我们共享了GPM前两级的网络权值并使用跨数据集的多粒度标签,使得所提出的Grapy-ML模型可以学习到更具区分性的特征表示并获得了最先进的性能。这点在三个流行基准(例如:CIHP 数据集)的大量实验中得到了证明。源代码已经对外公开,参见:https://github.com/Charleshhy/Grapy-ML。

特征图:提出的 Grapy-ML 图
三:多元贝叶斯非负矩阵分解
摘要:由于具有诱导含有语义的基于部位的表示的能力,非负矩阵分解(NMF)已被广泛应用于各种场景。但是,由于其目标函数的非凸性,部位分解通常不是唯一的,因此可能无法准确地发现数据内在的“部位”。在本文中,我们使用贝叶斯框架来处理这个问题。首先,基于有用部位应该是有区别的且覆盖性广的假设,赋予分解中的多个部位多元性先验,从而来诱导分解部位的正确性。其次,包含这种多元性先验的贝叶斯框架被建立了起来。该框架得到的分解部位既有极大似然诱导的较高的数据适合度,又有多元性先验带来的较高的可分离性。具体来说,多元性先验通过行列式点过程(DPP)建模,并无缝嵌入到贝叶斯 NMF 框架中。推断基于蒙特卡洛马尔可夫链(MCMC)的方法。最后,我们通过一个合成数据集和一个用于多标签学习(MLL)任务的实际数据集-MULAN-展示了该方法的优越性。

特征图:提议的架构的图示
四:生成-判别互补学习
摘要:目前最先进的深度学习方法大多是对给定输入特征的标签的条件分布进行建模的判别法。这种方法的成功在很大程度上依赖于高质量的带标签的实例,此类实例并不容易获得,特别是在候选类别数量增加的情况下。本文研究了互补学习问题。与普通标签不同,互补标签很容易获得,因为注释器只需要为每个实例随机选择的候选类别提供一个“是/否”的答案。我们提出了一种生成-判别互补学习方法。该方法通过对条件(判别)分布和实例(生成)分布的建模,对普通标签进行估计。我们将该方法称为互补条件生成对抗网络(CCGAN)。这种方法提高了预测普通标签的准确性,并能够在弱监督的情况下生成高质量的实例。除了大量的实证研究外,我们还从理论上证明,我们的模型可以从互补标记数据中检索出真实的条件分布。

特征图:模型结构
计算机视觉顶会CVPR 2020将于6月14日-19日在美国西雅图举行,今年的论文录取率降至22.1%(2019年录取率25.1%,2018年录取率29.6% )。虽然论文录取难度逐年增大,但是优必选悉尼大学人工智能中心在CVPR的成绩依旧斐然,后续将会带来12篇录取论文的详细介绍。
-

-
无人车“入春”,批量上路仍需“爬坡”
防控疫情的需求激发之下,代替人类送药、送餐送菜、消毒巡逻的无人车成了疫情期间的特殊尖兵。疫情过后,无人车配送是否...
2020-03-23 17:12
-

-
5G、AI、大数据的发展,对智慧城市会有什么影响
市场分调研机构Omdia的最新数据分析显示,全球智能城市人工智能(AI)软件市场将从6 738亿美元(2019年),在2025年将增长到4...
2020-04-07 17:55
-

-
机器人制造过程中的传感器技术之磁光效应传感器
现代电测技术日趋成熟,由于具有精度高、便于微机相连实现自动实时处理等优点,已经广泛应用在电气量和非电气量的测量中。
2020-04-07 17:56
-

-
微软不需要快速拥抱VR
微软经常在游戏领域开辟路径,扮演开拓者的角色,这一点体现在很多方面,包括微软的尖端技术(DX12终极版 DX光追),硬件(X...
2020-04-07 17:57
-

-
波音Starliner载人航天器再次展开测试
去年 12 月,波音为美国宇航局发射了未载人的 Starliner 航天器。然而由于技术问题,任务并没有按计划进行。作为 NASA ...
2020-04-07 17:58