对于机器学习开发者来说 创建一个应用有多难?
机器学习开发人员构建应用程序有多困难?事实上,您只需要知道Python代码,剩下的工作可以交给一个工具。最近,Streamlit的联合创始人Adrien Treuille写了一篇文章介绍机器学习工具开发框架——Streamlit,这是一个专门为机器学习工程师创建的免费开源应用构建框架。当您编写Python代码时,该工具可以实时更新您的应用程序。目前,“细流”的GitHub Star容量已超过3400,媒体热度已达到9000。

细流网站:https://streamlit.io/吉特百货地址:https://github.com/streamlit/streamlit/

使用300行Python代码,编写了一个能够实时执行神经网络推理的语义搜索引擎。
根据我的经验,每个非凡的机器学习项目都与内部工具集成在一起,这些工具充满了错误,难以维护。这些工具通常是用Jupyter笔记本和Flask应用程序编写的,它们很难部署,需要在客户端服务器架构(C/S架构)上进行推理,并且不能很好地与机器学习组件(如Tensorflow GPU会话)集成。
我第一次看到这样的工具是在卡内基梅隆大学,然后是在伯克利、谷歌X和Zoox。这些工具最初只是小型Jupyter笔记本:传感器校准工具、模拟比较应用、激光雷达校准应用、场景再现工具等。
当一个工具变得越来越重要时,项目经理就会参与进来:过程和需求都在增加。这些单独的项目变成了代码脚本,并逐渐发展成冗长的“维护噩梦”
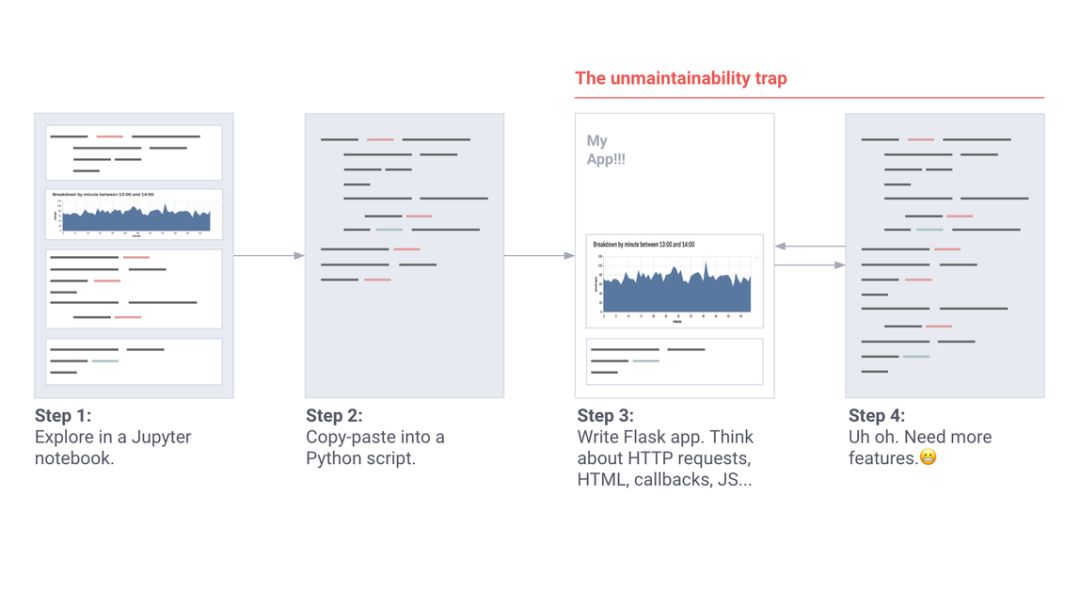
机器学习工程师创建应用程序的过程(即席)。
当一个工具至关重要时,我们将组建一个工具团队。他们熟练地写下Vue和React,并在笔记本电脑上粘贴带有声明性框架的贴纸。他们的设计过程是这样的:

工具团队构建应用程序的过程(干净整洁,从头开始)。
这简直太棒了!但是所有这些工具都需要新功能,比如每周上线的新功能。但是,工具团队可能同时支持10个以上的项目,他们会说,“我们将在两个月内更新您的工具。
我们回到了之前构建我们自己的工具的过程:部署烧瓶应用程序,编写HTML、CSS和JavaScript,并尝试版本控制从笔记本到样式表的一切。我的朋友蒂亚戈泰西拉和我在谷歌X工作,他们开始思考:如果构建工具像编写Python脚本一样简单呢?
我们希望没有工具团队,机器学习工程师也能构建好的应用程序。这些内部工具应该自然地作为机器学习工作流的副产品出现。编写这样的工具感觉就像在Jupyter中训练神经网络或执行特别分析!同时,我们也希望保留强大应用框架的灵活性。我们想创造让工程师们自豪的好工具。
我们想要的应用程序构建过程如下:

简化应用程序构建过程。
与优步、推特、缝合修复、Dropbox等的工程师一起。我们在一年内创建了Slylit,这是一个面向机器学习工程师的免费开源应用框架。细流的核心原则对于任何原型来说都更简单、更纯粹。
细流的核心原则如下:
1.拥抱蟒蛇
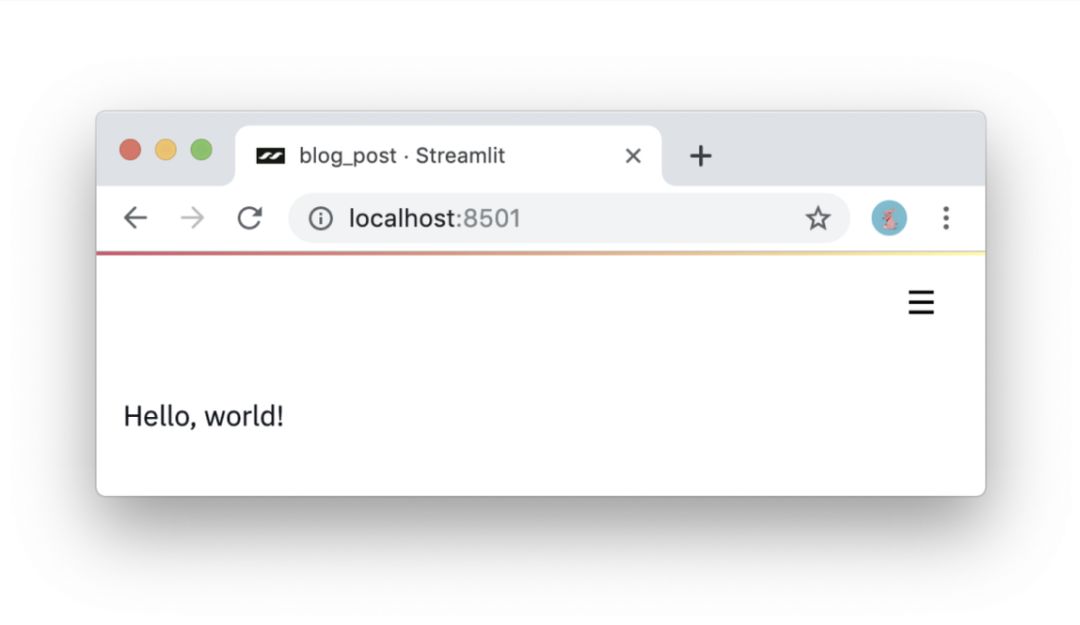
细流应用程序是一个完全从上到下运行的脚本,没有隐藏状态。您可以使用函数调用来处理代码。只要你能写Python脚本,你就能写流线应用。例如,您可以根据以下代码写入屏幕:
importstreamlitasstst.write(“你好,世界!”)
2.将小部件视为变量
细流中没有回调!每一次互动都只是脚本自上而下的重新运行。这种方法使代码非常简洁:
import streamlinetastx=ST . slider(' x ')ST . write(x,' squaredis ',x*x)
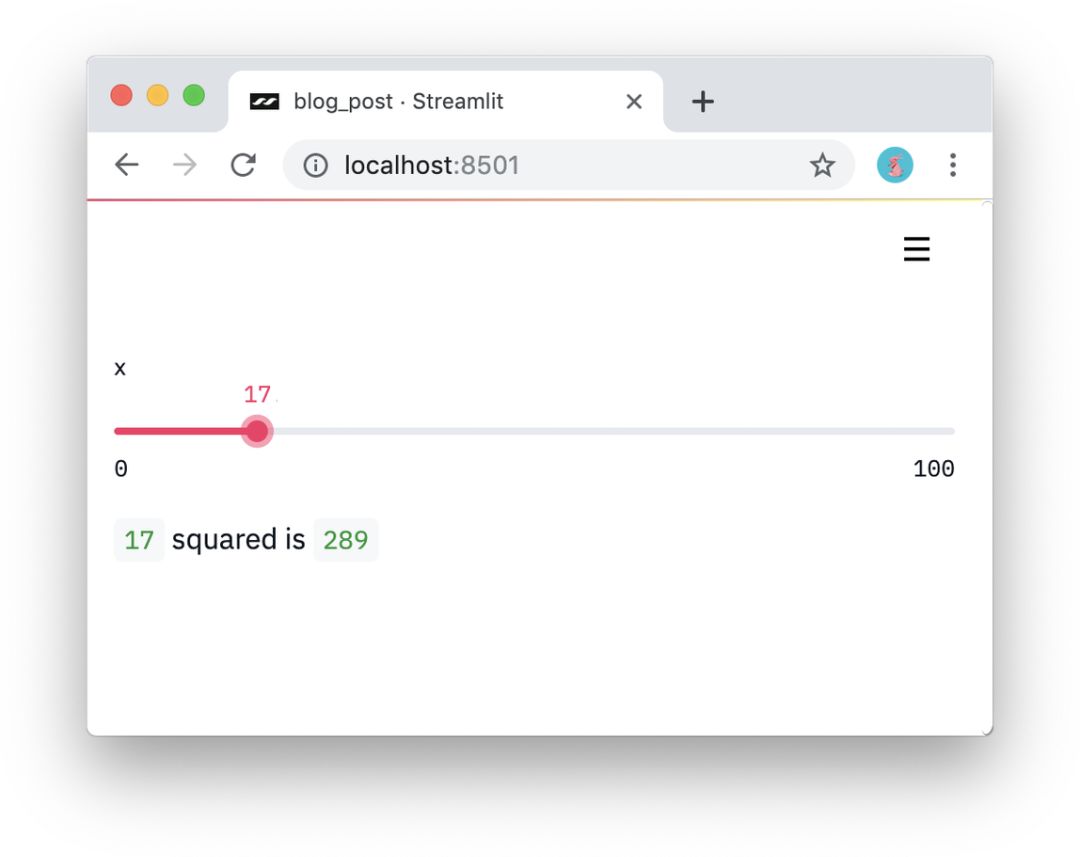
用3行代码编写的简化交互式应用程序。
3.重用数据和计算
如果您想下载大量数据或执行复杂的计算,该怎么办?关键是在多次运行中安全地重用信息。Streamlit引入了缓存原语,这就像一个连续的默认不可更改的数据存储,确保了Streamlit应用程序能够轻松安全地重用信息。例如,以下代码只能从乌达城自动驾驶仪项目(https://github.com/udacity/self-driving-car)下载一次数据,以获得一个简单快速的应用程序:
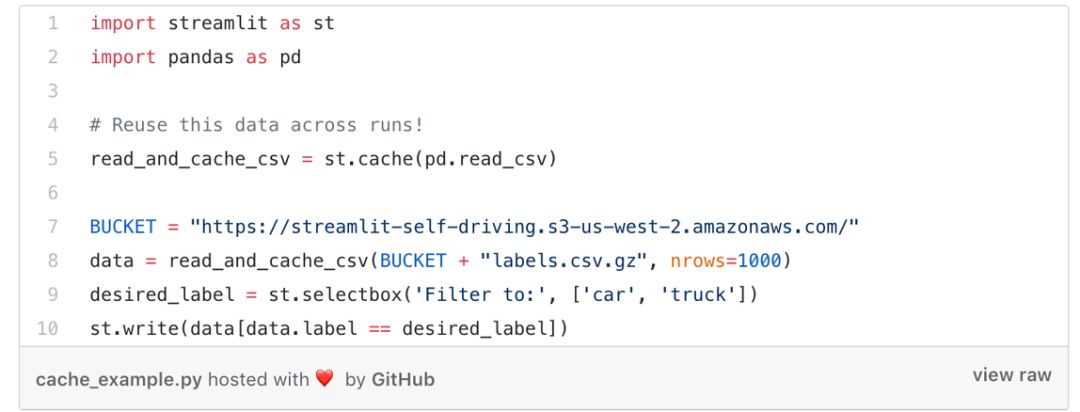
使用st.cache在多个细流运行中保存数据。有关代码操作说明,请参见:https://git . git hub.com/treulile/c 633 dc8 BC 86 EFA 98 EB 8 Abe 76478 aa 81 # git comment-3041475。
运行上面st.cache示例的输出。
简而言之,“简化”的工作流程如下:
每个用户交互都需要从头开始运行所有脚本。
Streamlit根据小部件状态为每个变量分配最新值。
缓存可确保简化数据和计算的重用。
如下图所示:
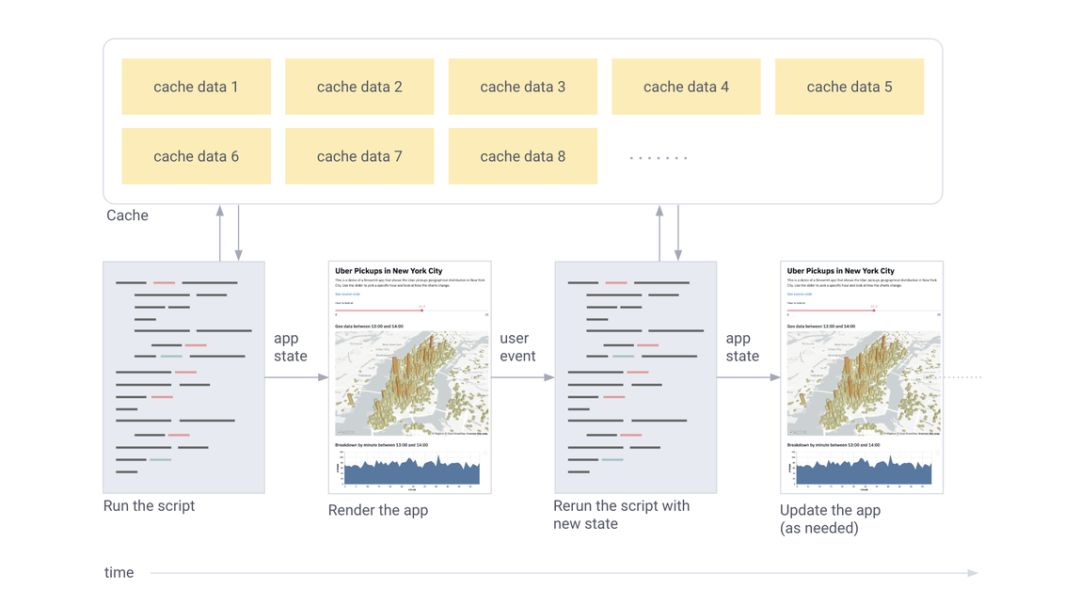
用户事件触发了Streamlit从头开始重新运行脚本。在不同的运行中只保留缓存。
如果你感兴趣,你可以马上试试!只需运行以下行:
网络浏览器将自动打开并转到本地的细流应用程序。如果没有浏览器窗口出现,只需点击链接。
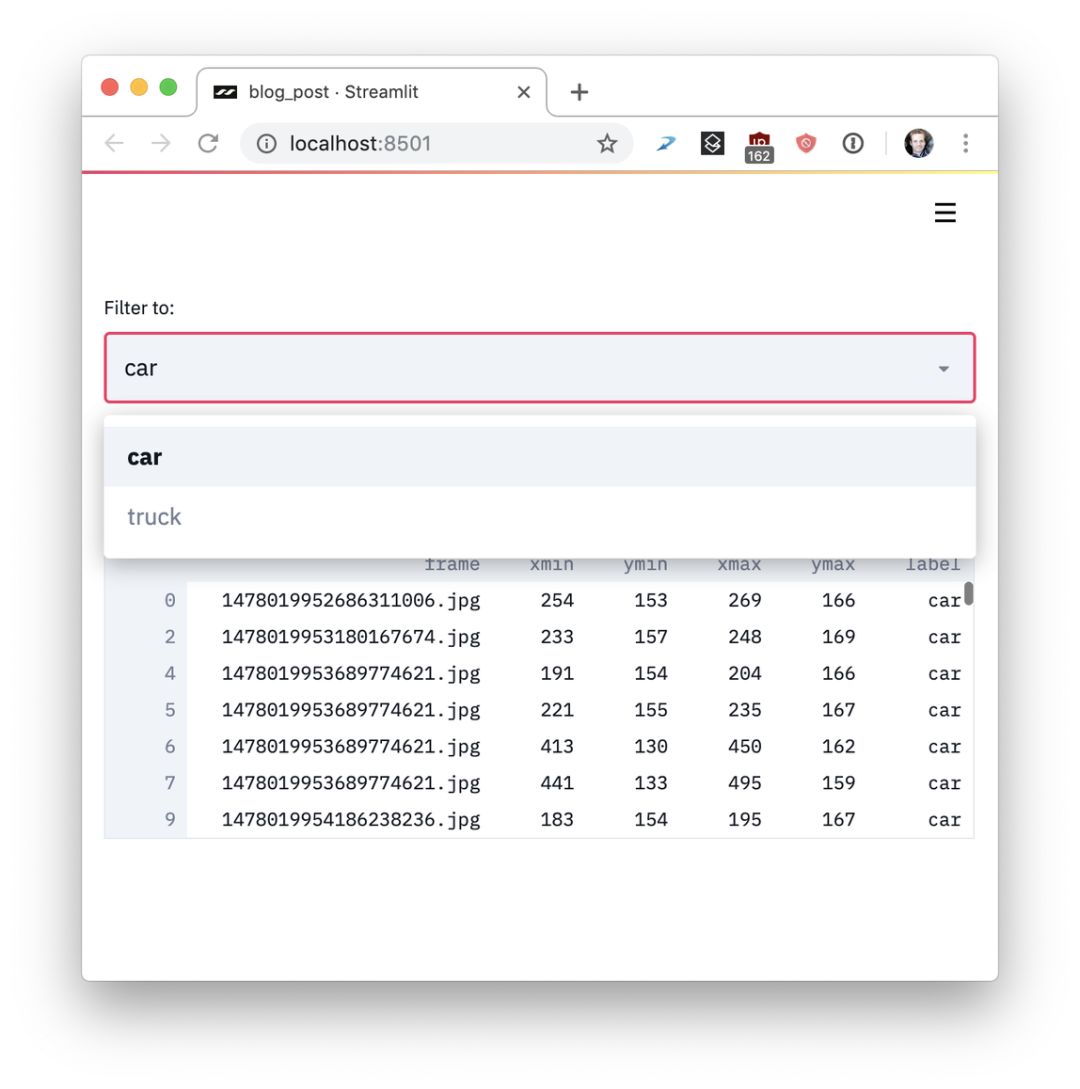
这些想法简单但有效,使用流线不会阻止你创建丰富有用的应用。当我在Zoox和谷歌X工作时,我看到自动驾驶汽车项目发展成几个需要搜索和理解的可视数据,包括用图像数据运行模型来比较性能。我看到的每个自动驾驶汽车项目都有一个完整的团队在开发工具。
在细流中构建这样的工具非常简单。下面的Streamlit演示可以在整个Udacity自动驾驶汽车照片数据集上执行语义搜索,可视化人类标记的真实价值标签,并在应用程序中实时运行完整的神经网络(YOLO)。

这个300行的流线演示结合了语义视觉搜索和交互式神经网络推理。
整个应用程序只有300行Python代码,其中大部分是机器学习代码。事实上,整个应用程序中只有23个细流调用。你可以试一试:

当我们与机器学习团队合作完成他们的项目时,我们逐渐意识到这些简单的想法会带来很多重要的好处:
细流应用程序是一个纯Python文件。您可以使用自己喜欢的编辑器和调试器。
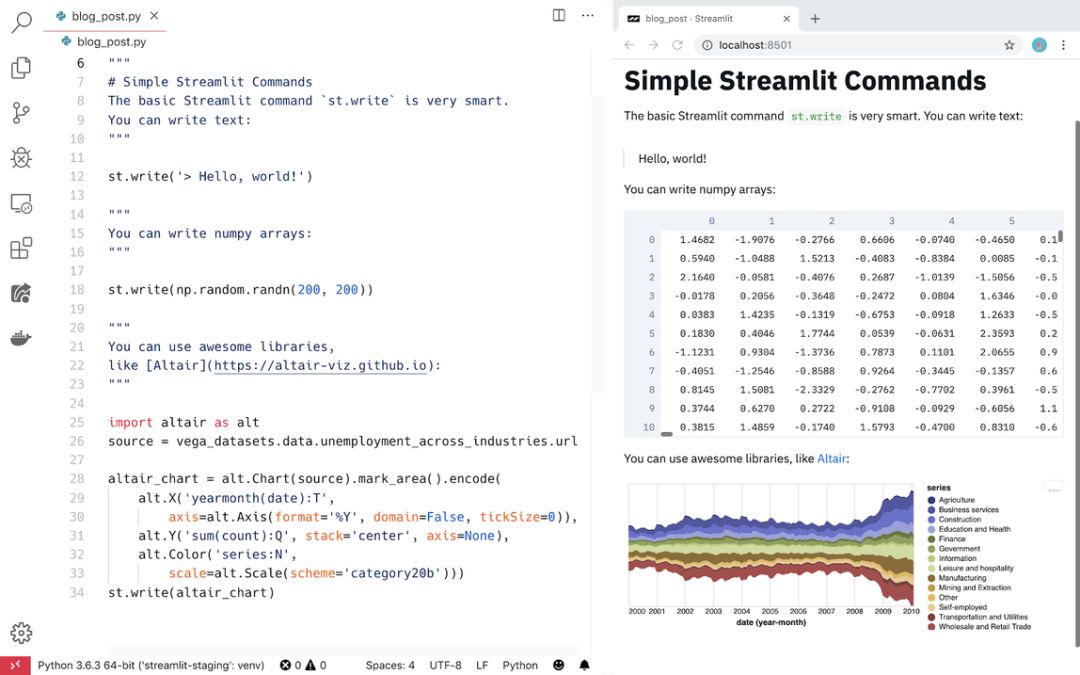
我喜欢使用VSCode编辑器(左)和Chrome(右)来构建应用程序。
纯Python代码可以与源代码控制软件(如Git)无缝接口,包括提交、请求、问题和注释。因为细流的底层语言是Python,所以您可以免费利用这些协作工具。
细流应用程序是一个Python脚本,因此您可以使用Git轻松地执行版本控制。
Streamlit提供了一个实时编程环境。当细流检测到源文件更改时,只需单击“总是重新运行”。
单击“总是重新运行”以确保实时编程。
缓存简化了计算过程。一系列缓存功能自动创建一个高效的计算过程!您可以尝试以下代码:
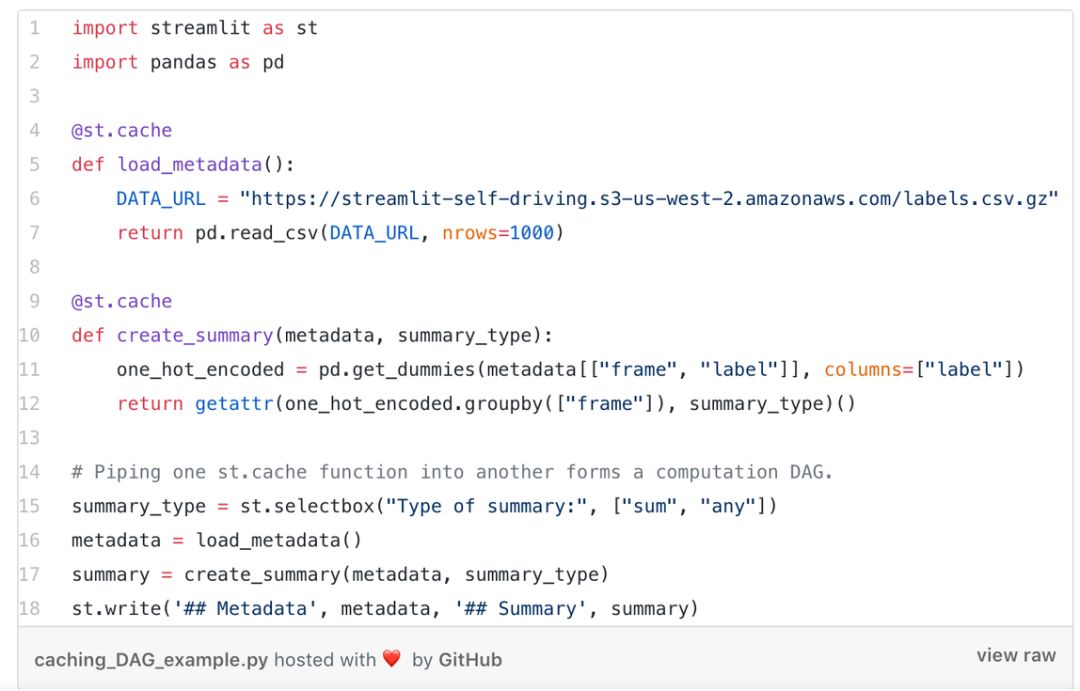
流线中的简单计算过程。运行上述代码,请参考说明:https://gist . git hub.com/treu ile/AC 7755 EB 37 c 63 a 78 fac 7 dfef 89 f 3517 e # git comment-3041436。
基本上,该过程包括加载元数据到创建摘要(加载元数据创建摘要)等步骤。每次脚本运行时,简化只需要重新计算流程的一个子集。
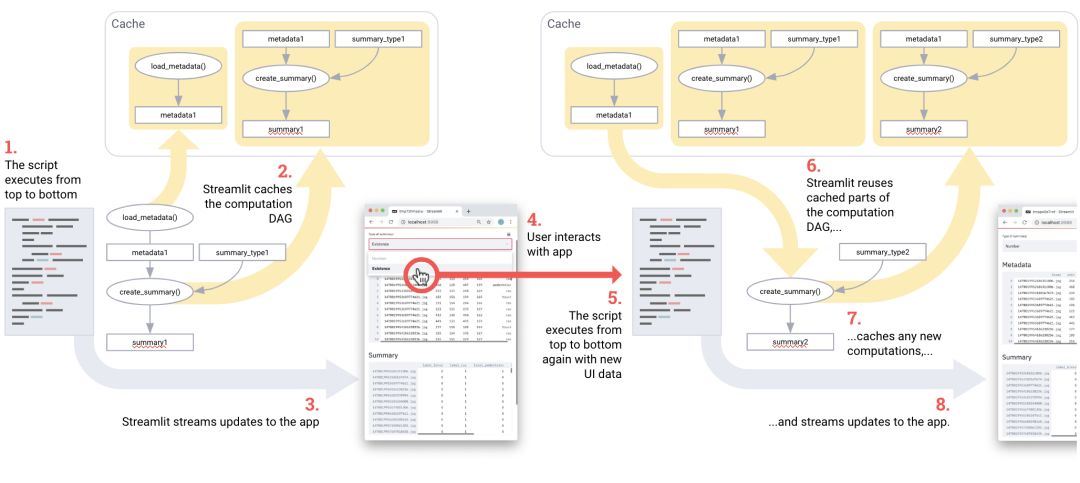
为了确保应用程序的可执行性,流线只计算更新用户界面所需的部分。
流线适用于GPU。Streamlit可以直接访问机器级原语(如TensorFlow、PyTorch)并补充这些库。例如,在下面的演示中,Streamlit的缓存存储了整个nvidia PGGAN。该方法使应用程序能够在用户更新左滑块时执行近乎即时的推理。
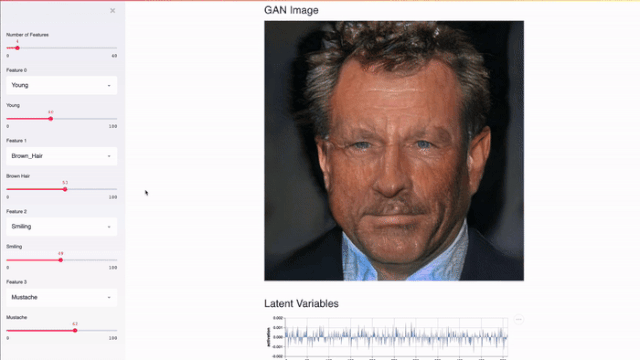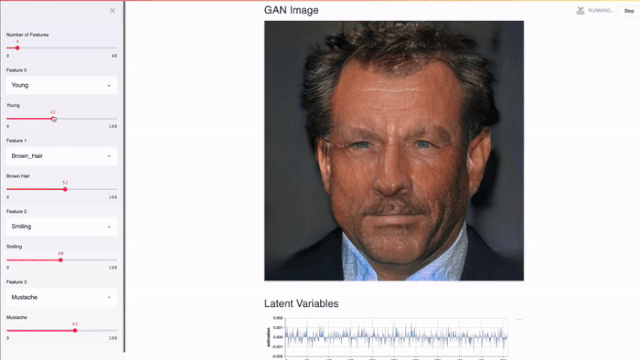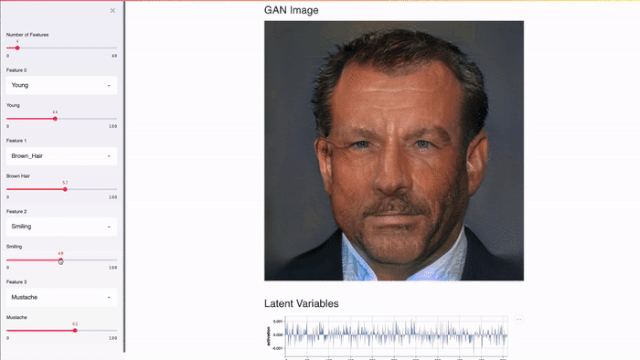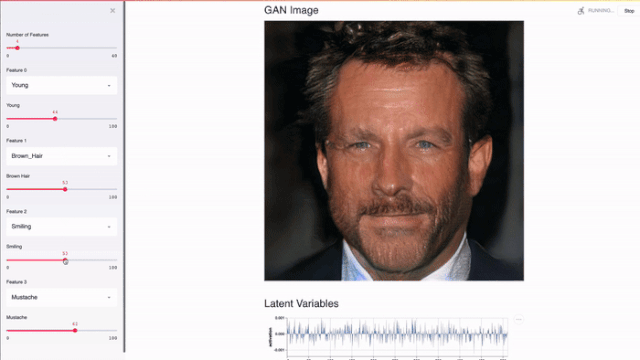
Streamlit应用程序使用TL-GAN来演示nvidia PGGAN的效果。
细流是一个免费的开源库,不是一个私人的网络应用。您可以在不提前联系我们的情况下在本地部署简化应用。您甚至可以在不联网的情况下在笔记本电脑上本地运行简化版。此外,“简化”可以逐渐用于现有项目。
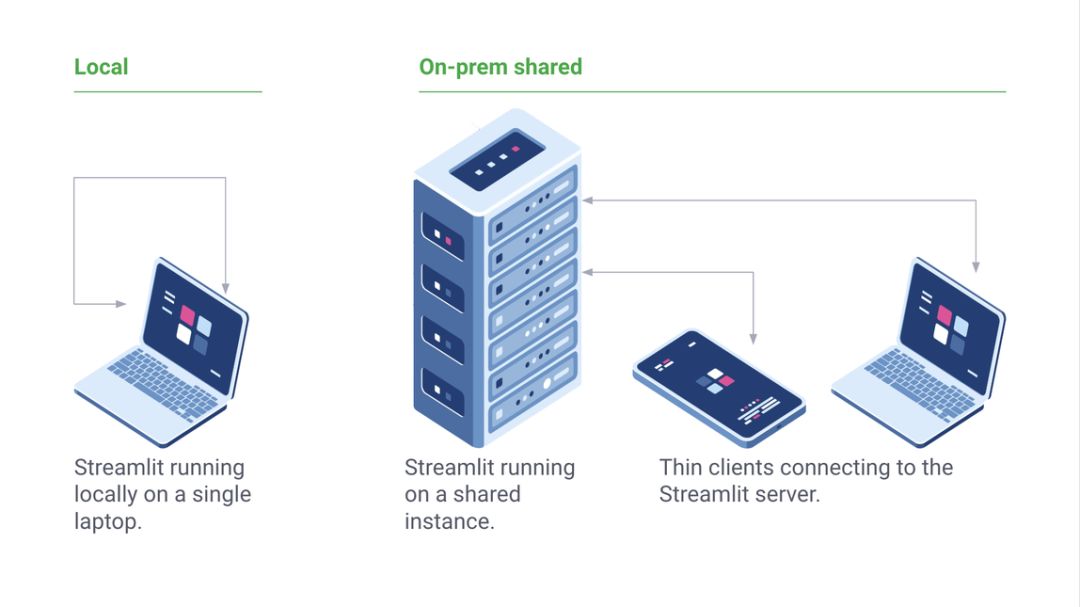
逐步使用流线的几种方法。
这些只是细流功能的冰山一角。最令人兴奋的是,这些原语可以很容易地形成复杂的应用程序,但它似乎只是简单的脚本。这将涉及架构的工作原理和功能,本文暂时不讨论这些。
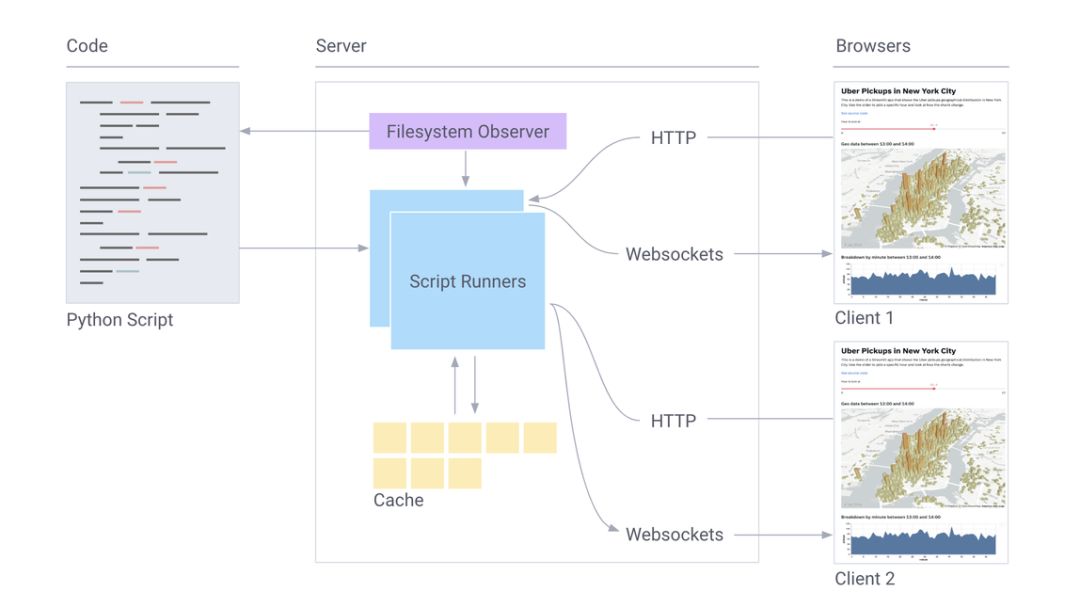
简化组件图。
我们很高兴与社区分享Slimit,并希望它能帮助您轻松地将Python脚本转化为美丽实用的机器学习应用程序。
-

-
无人车“入春”,批量上路仍需“爬坡”
防控疫情的需求激发之下,代替人类送药、送餐送菜、消毒巡逻的无人车成了疫情期间的特殊尖兵。疫情过后,无人车配送是否...
2020-03-23 17:12
-

-
5G、AI、大数据的发展,对智慧城市会有什么影响
市场分调研机构Omdia的最新数据分析显示,全球智能城市人工智能(AI)软件市场将从6 738亿美元(2019年),在2025年将增长到4...
2020-04-07 17:55
-

-
机器人制造过程中的传感器技术之磁光效应传感器
现代电测技术日趋成熟,由于具有精度高、便于微机相连实现自动实时处理等优点,已经广泛应用在电气量和非电气量的测量中。
2020-04-07 17:56
-

-
微软不需要快速拥抱VR
微软经常在游戏领域开辟路径,扮演开拓者的角色,这一点体现在很多方面,包括微软的尖端技术(DX12终极版 DX光追),硬件(X...
2020-04-07 17:57
-

-
波音Starliner载人航天器再次展开测试
去年 12 月,波音为美国宇航局发射了未载人的 Starliner 航天器。然而由于技术问题,任务并没有按计划进行。作为 NASA ...
2020-04-07 17:58