中国自然语言处理领域、经验和语料库建设技巧
我记得当我写毕业论文的时候,我经常担心语言材料。由于大多数自然语言处理问题都是监督问题,所以我们经常缺少的不是算法而是标签数据。这在汉语语料库中更为明显。今天,我想和大家分享一些在汉语自然语言处理和语言材料建设方面的经验和技巧。虽然读完这篇文章后,我可能无法完全解决语言材料的问题,但我或多或少会受到启发。
首先,我们将共享几个常见的数据采集通道。
国内外自然语言处理领域会议评价数据
相关研究机构、实验室和论文公布的数据集
国内外数据科学竞赛平台,凯格尔、天池、高赛、CCF等。
互联网公司举行自己的竞争,如百度、搜狐、智虎和腾讯,这些都是土豪,通常会花巨资来注释语言材料。
许多Github模型会带来一些数据。
虽然可以通过这些渠道收集到许多自然语言处理语料库,但这些“现成”的语料库往往与我们需要解决的自然语言处理问题不一致,所以我们必须想办法改变一些语料库。
通过API或开源模型标记语料库
例如,如果我们需要训练一个命名实体识别模型,我们可以使用bosonnlp或hanlp或蛮干tk来标记一些语料库。这些应用编程接口和模型有时只提供模型的预测结果,但不提供训练数据。然而,我们可以使用其他人训练的这些模型来构建数据。
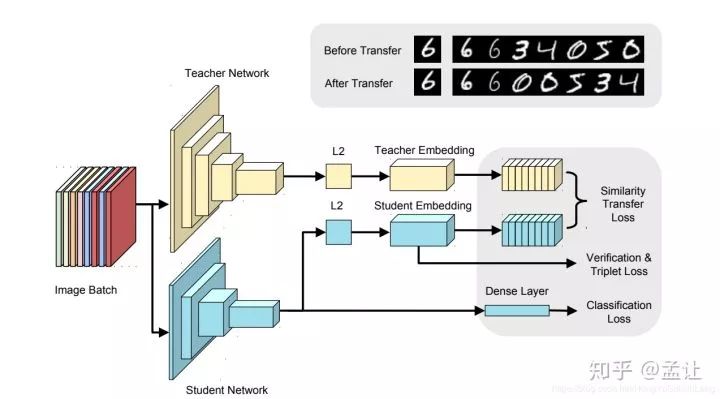
知识蒸馏
我们可以把别人训练的模型当作老师,然后用API标记的语料库把自己训练成学生。虽然结果无法达到与原始模型相同的效果,但也不算太差。这种方法可以帮助我们在项目的早期阶段快速推进项目,并在看到项目的效果之后找到优化迭代的方法。
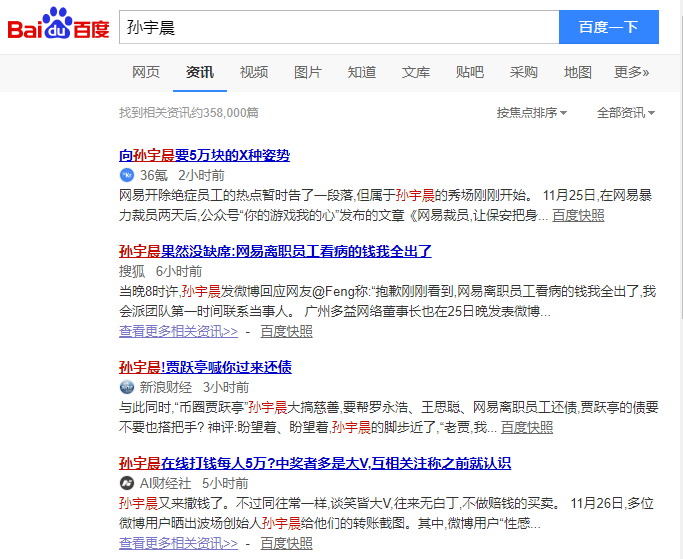
通过搜索引擎收集注释数据
假设我们需要制作一个NER模型,其中一种类型的实体是一个人的名字。或许我们可以考虑从网上下载一批新闻,然后标记这个人的名字。然而,这样做有一个问题。一篇有数千字的新闻通常只有几个人的名字,我们只需要这个人名字出现的句子部分,而不需要其他部分。直接给整篇文章贴标签是非常低效的。事实上,我们可以改变我们的思维,找到一个中文名称词库,然后把它放到百度上搜索。百度摘要返回的大部分结果基本上都是我们想要的语料库。我们可以通过爬行器向下爬行摘要,并自己过滤它。这种方法相当于在一些过滤和排序算法的帮助下,帮助我们快速找到要标记的语料库。
现有语料库的二次加工
有时,一些语料库与我们需要解决的任务相似,但它们完全不同。此时,我们可以尝试使用其他任务的语料库来构建所需的语料库。以百度2019信息抽取大赛为例。竞赛的任务是从以下内容中提取信息
文本“:”《逐风行》是百度文学纵横中文网特约撰稿人清水秋枫创作的一部东方幻想小说。这部小说于2014年4月28日正式发行
从这样的句子中提取实体和关系三元组
SPO _ LIST' : [{ '谓词' : '序列化网站','对象_类型' : '网站','主题_类型' : '网络小说','对象' : '纵横中文网','主题' : '流行逐一' },{ '预测' : '作者','对象_类型' : '人','主题_类型' : '图书作品','对象' : '清水'
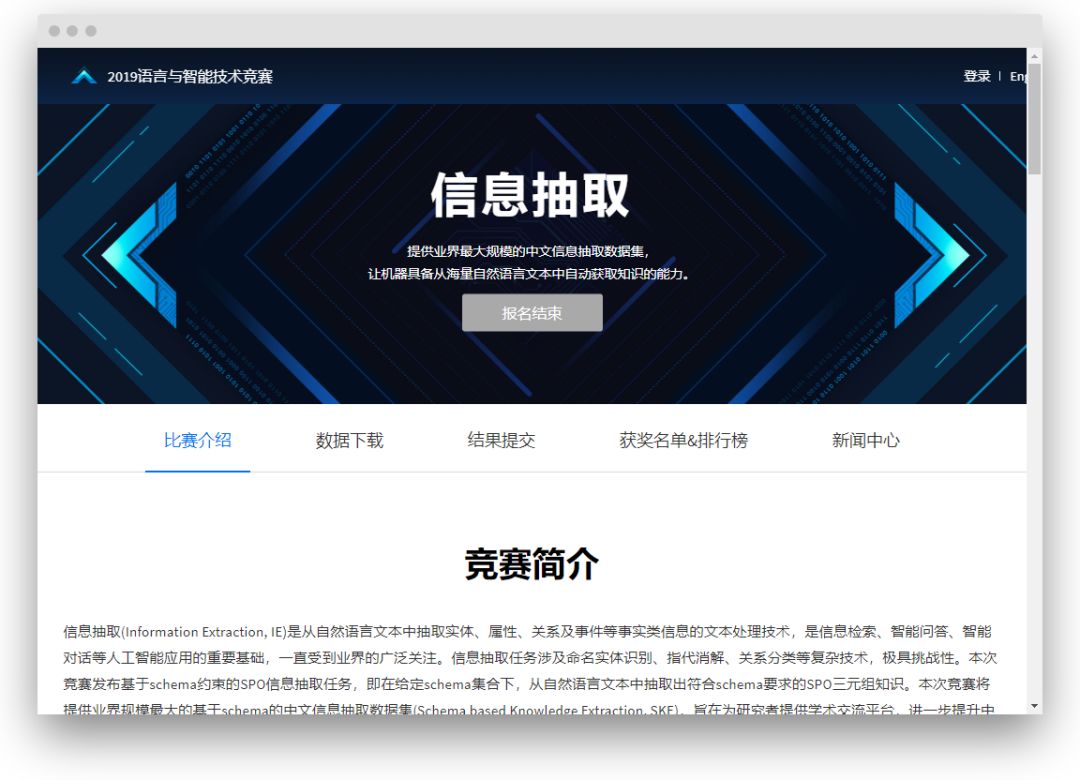
百度共提供了约17万条标注数据,标注数据质量相当高。训练数据以下列格式标记:
{'text':' 《逐风行》是百度文学纵横中文网特约撰稿人清水秋枫创作的一部东方幻想小说。《小说》于2014年4月28日正式发行,《SPO _ LIST》:[{《预测》:《连载网站》,《对象_类型》:《网站》,《主题_类型》:《网络小说》,《对象》:《中国在线》,《主题》:《大众化》},{《预测》:《作者》,《对象_类型》:《人》,《主题_类型》:《图书作品》
我们能从这些数据中构建出什么数据?
命名实体识别语料库
由于语料库中的每个实体都用实体类别来标记,命名实体识别任务的语料库可以通过实体类别来构建。这170,000个数据集提供了10多个类别的实体,如国家、城市、电影和电视作品、人、地方、企业和书籍。这些数据集,加上《人民日报》、msra和bosonnlp发布的NER数据,可以扩展更大的NER数据集。
开放关系抽取语料库
虽然数据集是面向闭域关系抽取的数据集,但经过修改后,它可以用于句子级的开域关系抽取任务。例如,我们可以构建一个基于序列标记的关系和实体联合提取模型。简单地说,给定(S,P,O)三元组和文本,我们可以提取一个表示关系的动宾短语或名词短语。例如,从百度文学纵横中文网签约作家清水秋枫创作的东方幻想小说《逐风行》开始,该小说就在2014年4月28日(清水秋枫,创作,《逐风行》)正式以这句话送出,从中提炼出这样一种三重关系。当然,要把它转换成一个适合开放关系抽取的语料库,还有一些工作要做。例如,原始语料库中的S和O是我们想要提取的内容,而P不是。因此,我们可能需要进行二次注释或建立另一个模型来预测p
许多公共语料库可以采用类似的方法。在这里,我会给你一些评论,而不是一个一个地介绍它们。
标记工具
如果一个工人想把工作做好,他必须首先磨利他的工具。贴标工具可以大大提高贴标效率。标记工具可以提供方便的快捷键和交互方法,这样我们可以同时标记更多的数据。同时,可以在贴标工具中嵌入一些人工智能辅助贴标功能,实现机器的自动贴标,而我们只需要修改和删除少量错误的贴标样本,进一步提高效率。
主动学习标签
在机器学习任务中,由于数据标注代价昂贵,如果能够从任务中设定标准,并通过理解任务来选择最重要的样本,这对模型的学习过程最有帮助,那么标注代价将大大降低,而主动学习就是解决这个问题。至于主动学习背后的理论细节,如果你感兴趣,你可以自己用谷歌搜索。这里有一个简单易懂的例子来简单解释。
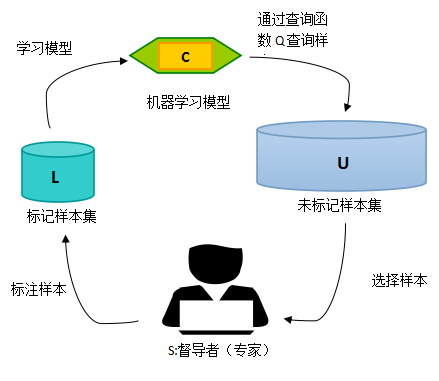
当然
还记得支持向量机中的“支持向量”吗?当我们进行分类时,并不是所有的点都对分界线的位置起着决定性的作用。即使您将10,000个样本点添加到离超平面特别远的区域,也不会影响分割线的位置,因为分割线由支持分割超平面的几个关键点(图中的三个)决定,因此这些关键点就是支持向量。从标记大数据的任务中学习,如果那些“重要”的样本能够被准确地标记,就有可能达到“事半功倍”的效果。
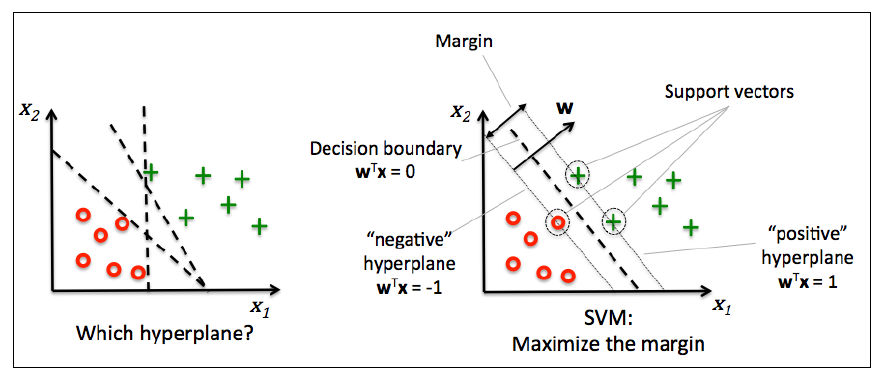

在上面的图中,随机标记的结果可以是B,精确度约为70%。右图是通过主动学习方法找到的标记点,因为这些点几乎形成了完美分界线的边界,所以使用与中间图相同数量的样本,但它可以达到大约90%的准确度。
弱监督数据标注
监督学习就是我们有一批高置信度的标注数据,并通过模型来拟合效果。弱监督学习意味着我们很难获得足够的高置信度标注数据,因此弱监督学习就是为了解决这个问题。
在这里,我想介绍一个斯坦福研究员的针对弱监督学习的开源浮潜框架。用这种方法生成的标签可以用来训练任何模型。浮潜已经被用于处理图像数据、自然语言监控、半结构化数据处理、自动训练集生成等特定用途。
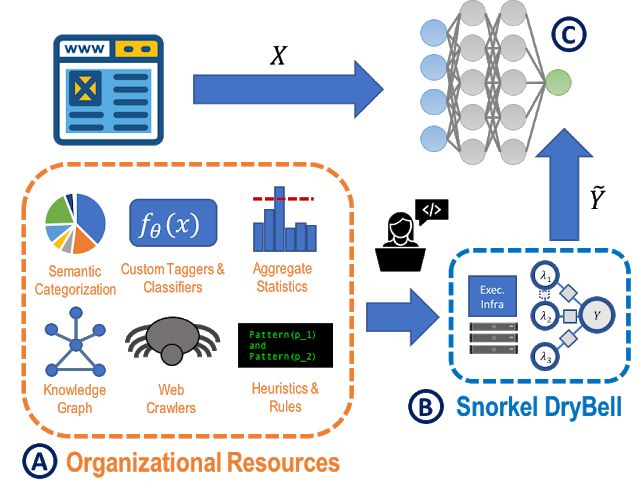
浮潜整合了各种各样的知识来源作为薄弱的监督。我们只需要在基于MapReduce模板的管道中编写标记函数。每个标签函数接受由数据点生成的概率标签,并选择返回无(无标签)或输出标签。在编写标记函数时,我们可以用所有可用的知识来标记我们的数据,这些知识可能包括人工规则、知识地图、现有模型、统计信息、网页等。
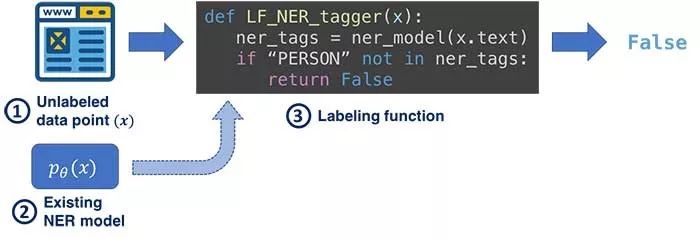
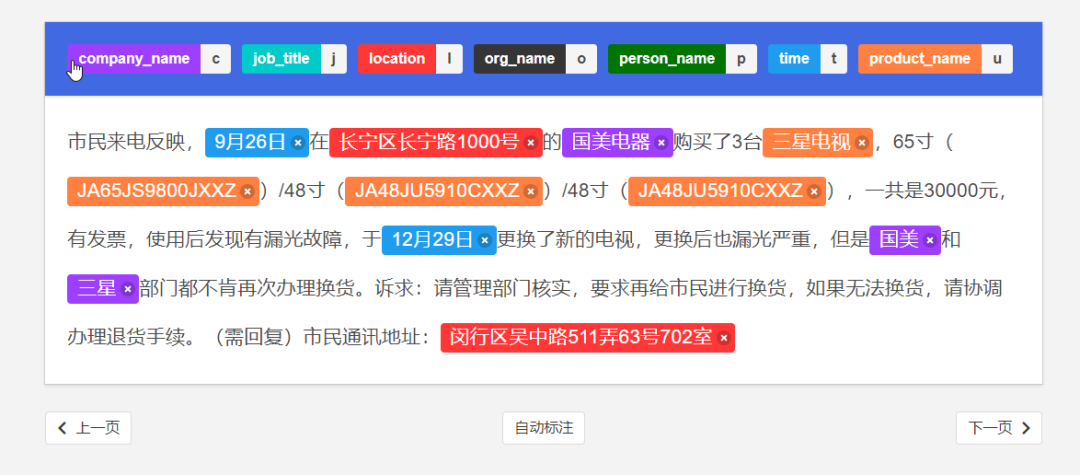
如上图所示,假设我们正在执行NER任务并需要标记姓名,可用于构建标记功能的知识如下:
是人类名词库中的文本
来自NLP工具包的位置标签,如jieba、hanlp等。
文本是知识地图中的人类实体吗
基于上述知识,我们可以编写多个标记函数。当然,浮潜标记的数据是有噪声的,甚至许多标记函数给出了冲突的结果。我们根本不用担心这个,因为浮潜已经为这些问题提供了解决方案。
发挥项目的效果,向公司申请资源。
最后,我们可以想到着陆场景和算法的价值,讲一个好故事,争取公司和老板的资源!
-

-
无人车“入春”,批量上路仍需“爬坡”
防控疫情的需求激发之下,代替人类送药、送餐送菜、消毒巡逻的无人车成了疫情期间的特殊尖兵。疫情过后,无人车配送是否...
2020-03-23 17:12
-

-
5G、AI、大数据的发展,对智慧城市会有什么影响
市场分调研机构Omdia的最新数据分析显示,全球智能城市人工智能(AI)软件市场将从6 738亿美元(2019年),在2025年将增长到4...
2020-04-07 17:55
-

-
机器人制造过程中的传感器技术之磁光效应传感器
现代电测技术日趋成熟,由于具有精度高、便于微机相连实现自动实时处理等优点,已经广泛应用在电气量和非电气量的测量中。
2020-04-07 17:56
-

-
微软不需要快速拥抱VR
微软经常在游戏领域开辟路径,扮演开拓者的角色,这一点体现在很多方面,包括微软的尖端技术(DX12终极版 DX光追),硬件(X...
2020-04-07 17:57
-

-
波音Starliner载人航天器再次展开测试
去年 12 月,波音为美国宇航局发射了未载人的 Starliner 航天器。然而由于技术问题,任务并没有按计划进行。作为 NASA ...
2020-04-07 17:58